4 Datasets
A dataset is a collection of values, usually either numbers (if quantitative) or strings (if qualitative). Values are organized in two ways. Every value belongs to a variable and an observation. A variable contains all values that measure the same underlying attribute (like height, temperature, duration) across units. An observation contains all values measured on the same unit (like a person, or a day, or a race) across attributes. .
4.1 Structure
The W3C RDF (Resource Description Framework) standard is a standard model for data interchange on the internet. RDF makes sure that not only texts, but datasets, sound recordings, and various digital assets can work seamlessly over the internet.
The RDF Data Cube Vocabulary is the W3C standard to publish multi-dimensional data11, such as statistics, on the web in such a way that it can be linked to related data sets and concepts using the W3C RDF standard. The model underpinning the Data Cube vocabulary is compatible with the cube model that underlies SDMX (Statistical Data and Metadata eXchange), an ISO standard for exchanging and sharing statistical data and metadata among organizations. While they are not yet fully harmonized, our work can be seen as very highly standardized, because we rely on a very small part of the RDF Data Cube Vocabulary
The SDMX initiative sets standards to facilitate the exchange of statistical data and metadata using modern information technology. SDMX has also been published as an ISO International Standard (ISO 17369).
4.1.1 The data cube model
Statistical services usually use a the data cube model for publishing or exchanging data. Our data observatories follow this model with a subjective interpretation.
A cube is organized according to a set of dimensions, attributes and measures. We collectively call these components.
The dimension components serve to identify the observations. A set of values for all the dimension components is sufficient to identify a single observation. Examples of dimensions include the time to which the observation applies, or a geographic region which the observation covers. We always use two dimensions in our releases: GEO for the geographical reference are and TIME for the reference period in time.
The measure components represent the phenomenon being observed. Our measurement is always called VALUE in our releases and in the Rest API.
The attribute components allow us to qualify and interpret the observed value(s). They enable specification of the units of measure, any scaling factors and metadata such as the status of the observation (e.g. estimated, provisional). We use three attributes: UNIT for the unit of measure, OBS_STATUS for the status of the VALUE (actual, estimated, forecasted, missing…), and METHOD for the estimation or forecasting used to fill non-actual values. The FREQ attribute states if the data is collected annually, monthly, daily.
We also use an observation ID for OBS to uniquely identify an observation.
4.1.2 Use of standard code lists
The goal of our statcodelists R package is to promote the reuse and exchange of statistical information and related metadata with making the internationally standardized SDMX code lists available for the R user. SDMX has been published as an ISO International Standard (ISO 17369). The metadata definitions, including the codelists are updated regularly according to the standard. The authoritative version of the code lists made available in this package is https://sdmx.org/?page_id=3215/.

Figure 4.1: Our statcodelists data package is released on CRAN and available for anybody who uses the R statistical system.
You can install the R package from Github (it is under peer-review on CRAN.)
install.packages("statcodelists")4.1.3 From data cubes to tidy datasets
Statistical data providers usually maintain data products that have a high-level of dimensionality. Data cubes are efficient in providing information, but they are not structured for the final users, a data analyst or a data visualization professional. For any realistic application, ther dimensionality must be reduced. Most usual charts, like a scatterplot, a barchart, or piechart can only visualize 1-3 dimensions (coloring being the last dimension.) Our data observatory chooses usability over data variability.
The tidy data concept is a data science concept to organize datasets in a way that they need the least processing in use. Because data analysis usually spend about 80% of their time with formmatting data—and often make many mistakes in this process–, it is desirable to publish data in a format that will require the least steps in analytical uses. The “tidy datasets provide a standardized way to link the structure of a dataset (its physical layout) with its semantics (its meaning).”12 The tidy data principles are not standards: they can be seen as rules that facilitate efficient, less errorprone work with the data.
Our observatories produce and disseminate datasets that adhere to the three tidy data principles, and follow the organizational structure of the SDMX datasets. They are equipped with metadata that makes them work well with other RDF resources. They are low-dimension tidy datasets following some basic rules.
4.2 Our dataset specification
Each variable is represented in a column. (Tidy principle)
Each observation is represented in a row. (Tidy principle)
Each dataset has a single unit of measure, and when different units of measures are used, they are placed in different tables.(Tidy principle)
The dataset is organized into observation identifiers, at least two statistical dimensions (the geographical and time concepts), measurements of the observation, observation unit codes, and at least 2 observational attributes. The datasets common attributes are addes as metadata in a codebook that are connected unambigously to the dataset. The most important common attribute is the single unit of measure used in the dataset.
The unit of measure is coded with the use of standard statistical codes, which are included in the dataset, or in its codebook. This allows the the labelling of the unit in many natural languages. (We use SDMX Codelists, see earlier in section 4.1.2.)
The
OBS_STATUS(observation status) clearly indicates if the observation is measured, estimated, imputed, or missing (by default, coded withO). Whenever possible, theOmissing observation status is more precisely categorized into the missingness codesML,H,Q.
Figure 4.2: Example of a dataset
We provide further processing information to each codebook:
A further codebook URI link is given to any observations that have the observation statuses
F(forecasted),I(value imputed by a receiving agency), and whenever we collected the data or we have the information from the collecting agency, also to observations marked withE(estimated by collecting agency).We also give a similar indication to any seasonal adjustment applied for time series.
4.3 Our added value to the contents
4.3.1 Missing values, interpolations and forecasts
If you take a look at our demonstration dataset, you will notice that the observation status has three values: A, E, and F.
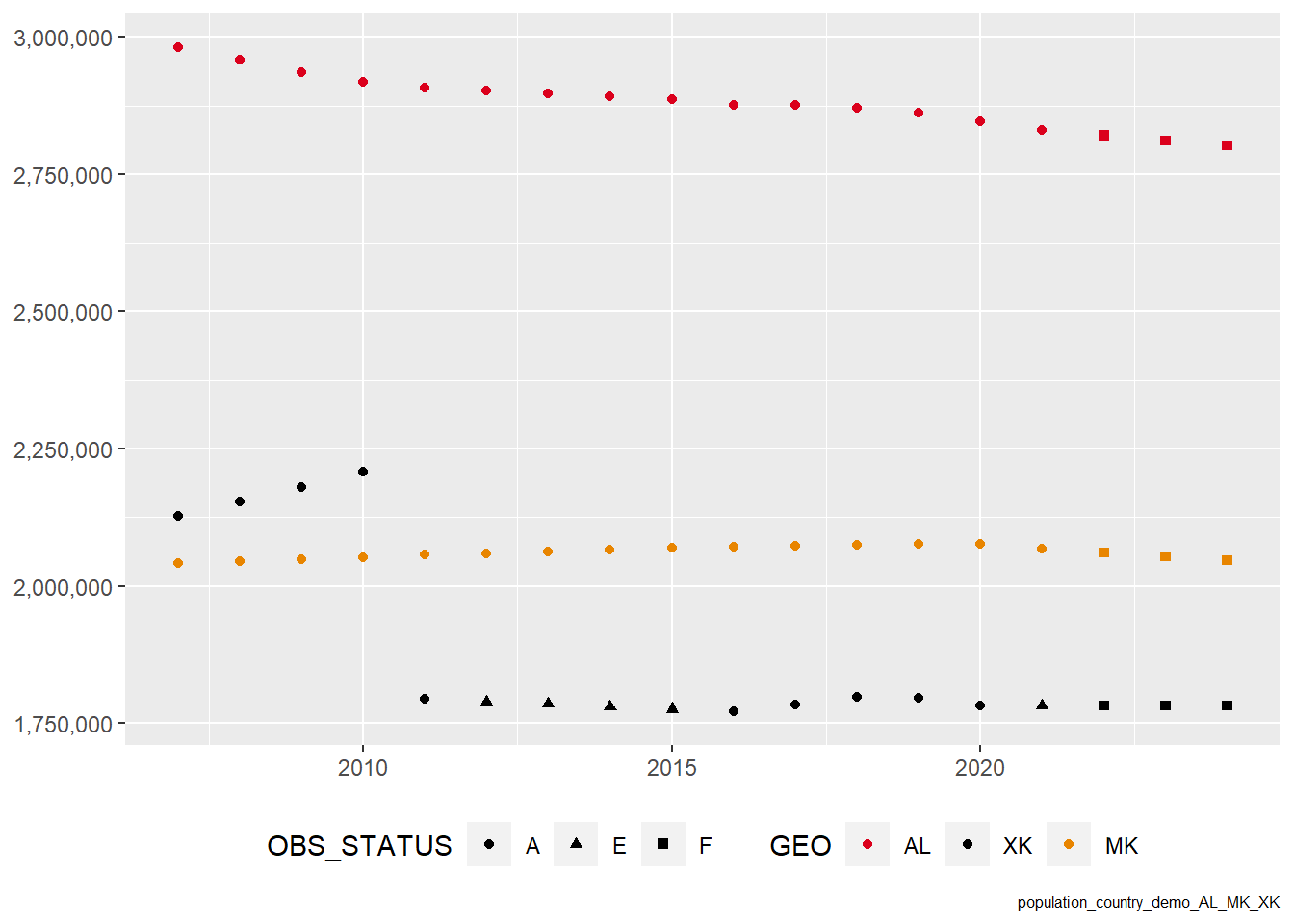
Figure 4.3: The visualization of our two-dimensional dataaset (with geography and time)
The A values are actual values that we received from the Eurostat statistical agency. We chose Albania, Kosovo and North Macedonia because they often have missing values—which in most applications, including machine learning applications, statistical regression tools, or in visualization would cause a problem.
One of the most time consuming and error-prone processes are dealing with such missing data. Most data analysts or visualization users do not know how to deal with them. In most cases—although the practice of Eurostat is changing–, statistical agencies refrain from such interpretations of the data, and report these observations as missing.
Our dataset is subjective: it has an authored creator, a curator of our data observatory, who knows how to make (and document!) correct interpolations and extrapolations, and we fill the dataset with estimates and forecasts that are made with reliable, peer-reviewed algorithms, run in controlled computational environment by data scientists.
Imputation refers to the professional filling of the missing values. Summarizing the OBS_STATUS and METHOD attributes of our datasets shows what happened here.
if (! is_word_output) {
population_ds %>%
group_by( .data$OBS_STATUS, .data$METHOD) %>%
tally() %>%
kbl()
} else {
print ("Not shown in Word output")
}For professionally interpolating missing values in the dataset (in the past), we used the 8.1.6 version of forecast, a widely used, and scientifically peer-reviewed statistical application of Rob Hyndman, calling the na.interp function with period=1 for linear interpolation.
For nowcasting (values about the present that are not yet computed by the statistical agency, or not yet disclosed) and forecasting the future, we used the same software, but this time, using the generic forecast method to find the best forecasting model for future values. The best models were Exponential smoothing or ETS models with different settings. The knowledgable reader may be familiar with the taxonomy of ETS models. However, most users of statistical products are not familiar with them.
Let’s see another example where we cannot fill the missing observations. Somebody collected pebbles in the former Czechoslovakia: in 1992 4 pebbles, and 2-2 pebbles in after the breakup in Czechia and Slovakia. There are no Czech and Slovak values available for 1992—these separate countries did not exist yet. The data is coded as M—data cannot exist. In 1994, unfortuantely, the Czech data was not collected, or the data was lost. It is coded as L.
Figure 4.4: Logically missing values
For the casual reader, the missingness codes do not make a difference. However, they have an important meaning. If we were about to create a European average pebble number, we should not worry about the missing Czechoslovak data for 1994: the country was succeeded by two other countries, and it would be a mistake to add a calculated data for CS. While we can create an estimated (imputed) value for backward compatibility for the former Czechoslovakia, adding this imputed CS value and both the CZ and SK value to a Euroepan sum and average would be double counting Czechia and Slovakia.
However, in most statistical applications, we must do something with L. Czechia existed in 1994, the pebbles were there, and if we cannot count an European sum or average without Czechia. Filling in a zero value would distort the European sum or average in an unjustified way. Our data observatory will change the L observation to I after filling in an estimated value for Czechia. This means that we imputed a calculated number. We will add create an method column to explain what imputation method (last observation carry forward? linear interpolation, extrapolation) we applied to fill out this missing information.
If we ran the excellent forecast software on these values, provided that we have enough data for CS, CZ, and SK values, it would fill them with “estimates”. The computer does not know that CS referes to a country that have not existed since 1 January 1993. This is why we do not robotize entirely our data pipelines. We need human agency, knowledgable curators, who know the world that the statistical indicator describes, and the limitations of software solutions.